Pythondaki mechanize modülü tedavülde
Emulating a Browser diye geçiyor. Bu modülü kullanarak en basitinden bir web sayfasındaki html formlarını doldurup işlemler yapabilirsiniz. Sonraki yazıların birinde mechanize modülü ile twitter ve facebook login sayfalarını kullanarak Brute Force yapan bir tool ekleyebilirim.
Mechanize modülünü sisteminizde pip yüklü ise
pip install mechanize yazarak, pip yüklü değilse şu adresten sisteminize uygun halini (tar.gz veya rar) indirebilirsiniz. İndirdikten sonra mechanize klasörünü gelip python setup.py install yazarak modülü sisteme yükleme işlemini gerçekleştirebilirsiniz. Başlayalım;import mechanize # bildiğiniz gibi modülü import ediyoruz kullanabilmek içinurl = "www.ornekadres.com" # linklerini alacağımız sitenin adresimech = mechanize.Browser() # mech objemizi olusturduk
mech.open(url) # belirlediğimiz adrese gidiyoruz.
for link in mech.links():
print "[*] text: %s -- url: %s " %(link.text,link.url)
buradaki link.text
<a> </a> tagları arasındaki texti veriyor, link.url ise hostname'den sonraki url'i veriyor bize.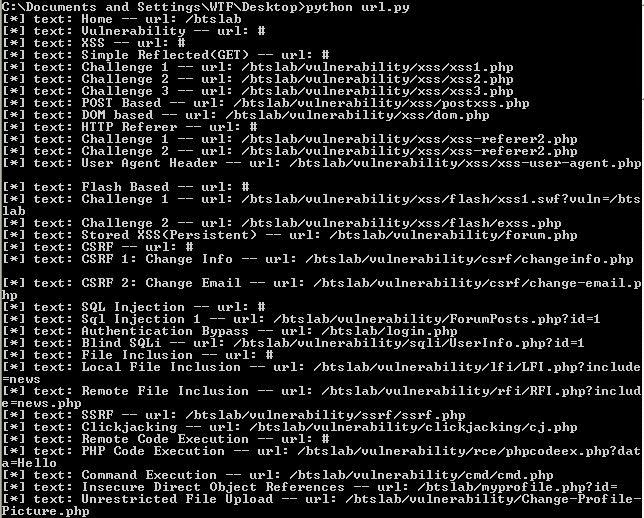
En basit şekliyle sayfadaki linkleri bu yöntemle crawl edebilirsiniz. Dilerseniz urlparse modülünü kullanarak linkleri belli bir düzenle toplayabilirsiniz.
İsterseniz farklı methodları da kullanabilirsiniz neticede browser emulating işini yapıyor mechanize modülü.
- mech.set_cookie("Cookie degeri") #bu method ile işlemleri yapacağınız web sayfasına cookie değeri ekleyebiliyorsunuz.
- mech.addheaders = [('User-agent', "Mozilla/5.0 (Windows NT 5.1; rv:32.0) Gecko/20100101 Firefox/32.0")] # parametrelerden anlayacağınız gibi User Agent bilgisi ekliyor.
- mech.add_header("Referer", "http://www.falanfisman.com)
- mech.set_proxy("proxyAdres:Port","http") # proxy kullanabiliyoruz isteklerimizi yaparken.



Hiç yorum yok:
Yorum Gönder